The Evolution of Prompt Engineering : From Art to Science

The field of prompt engineering has undergone significant changes since the rise of Large Language Models. This article explores the evolution from traditional prompt engineering to more sophisticated approaches like prompt compiling and optimization.
The Decline of Traditional Prompt Engineering
The initial excitement surrounding language models gave rise to prompt engineering, a technique aimed at crafting specific inputs to get the desired outputs. However, this approach faced several challenges:
- Lack of Scalability: The artisan nature of prompt engineering made it difficult to scale and made it task-specific.
- Unpredictability: The inherent uncertainty in language model outputs reduced reliability.
- Model Dependency: Prompts often needed to be tailored for specific models, limiting portability.
- Skill Barrier: Effective prompt engineering required a mix of creativity and technical knowledge, creating a high skill barrier.
 Key challenges in traditional prompt engineering ref
Key challenges in traditional prompt engineering ref
These challenges were particularly evident in scenarios where prompt accuracy was critical. For instance, if a prompt had 0% or 100% accuracy, it could be considered trustworthy. However, accuracy around 70% or less posed significant challenges, forcing engineers into a cycle of trial and error.
In complex systems, such as sequential agents, an untraced output error could lead to completely incorrect results, which might be difficult to identify amidst thousands or hundreds of thousands of tokens.
The Necessity of Prompt Compiling
Prompt compiling emerged as a response to the shortcomings of traditional prompt engineering. This approach offers several advantages:
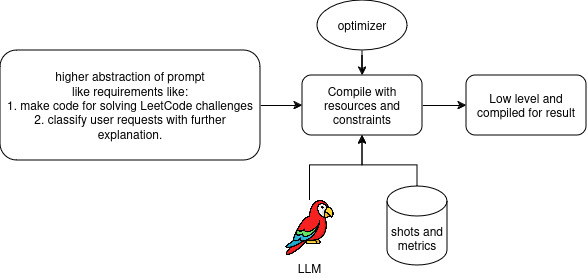 The process of prompt compiling
The process of prompt compiling
- Abstraction: Developers can focus on desired outcomes rather than specific prompt wording.
- Automated Optimization: Systems can refine prompts based on specified constraints and assertions.
- Consistency: It aims to produce more reliable results across different LLM versions.
- Self-Refinement: Incorporates strategies for automatic improvement during inference.
- Versioning and Maintenance: Facilitates easier updating and maintenance of prompts as models evolve.
- Performance Metrics: Enables more systematic evaluation of prompt effectiveness.
Prompt compiling represents a shift towards a more structured and scientific approach to interacting with language models. It addresses the need for:
- Reproducibility: Ensuring consistent results across different runs and environments.
- Scalability: Allowing for the efficient creation and management of prompts for large-scale applications.
- Adaptability: Enabling prompts to adjust to different models and use cases with minimal manual intervention.
DSPy: A Pioneering Solution
DSPy (Domain-Specific Programming for Language Models) stands out as an innovative tool in LLM programming, addressing the limitations of conventional prompt engineering. While it’s not yet a perfect or final solution, it represents a significant step forward.
DSPy programs consist of multiple calls to Language Models (LMs), stacked together as DSPy modules. Each DSPy module has internal parameters of three kinds:
- LM weights
- Instructions
- Demonstrations of the input/output behavior
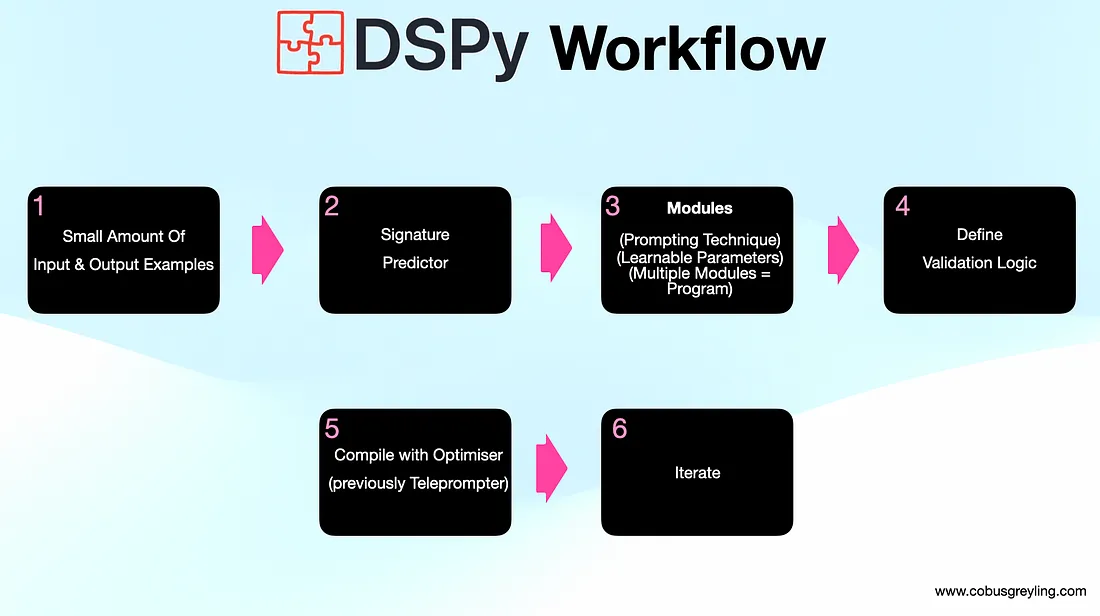 Traditional prompt engineering vs. DSPy approach
Traditional prompt engineering vs. DSPy approach
This approach offers several benefits:
- Flexibility: Adapts to different LLMs and use cases.
- Efficiency: Reduces the time and effort required to develop LLM applications.
- Robustness: Improves the reliability and consistency of LLM outputs.
Prompt Optimization and DSPy’s Optimizers
Prompt optimization techniques aim to refine and improve prompts for better performance. DSPy introduces the concept of optimizers, which are algorithms that can tune the parameters of a DSPy program to maximize specified metrics, such as accuracy.
[!NOTE] A DSPy optimizer is an algorithm that can tune the parameters of a DSPy program (i.e., the prompts and/or the LM weights) to maximize the metrics you specify, like accuracy.
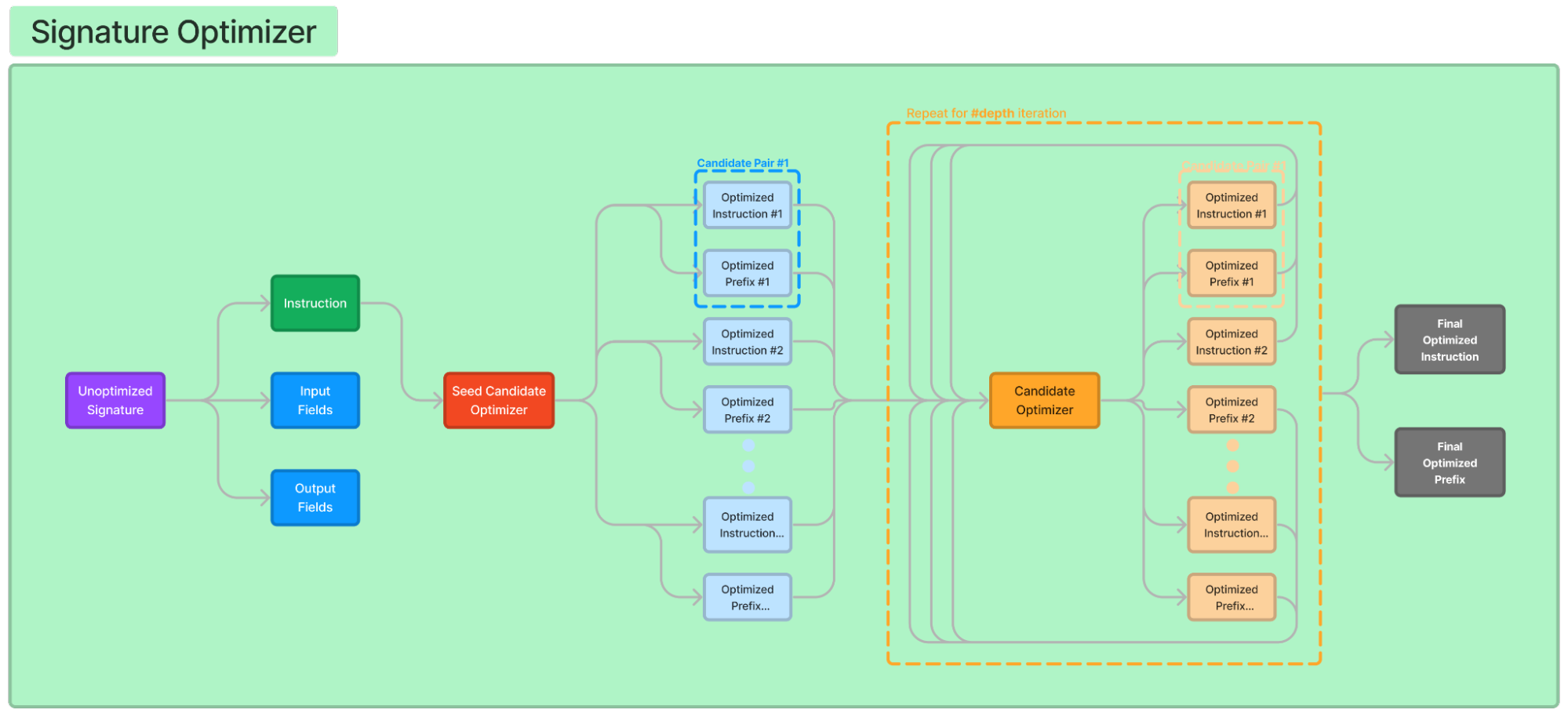 Visualization of a DSPy optimizer refining a prompt
Visualization of a DSPy optimizer refining a prompt
Given a metric, DSPy can optimize all three types of parameters (LM weights, instructions, and demonstrations) with multi-stage optimization algorithms. These can combine gradient descent (for LM weights) and discrete LM-driven optimization for crafting/updating instructions and creating/validating demonstrations.
DSPy’s teleprompter is a specific implementation that introduces:
- Multi-model Compatibility: Designs prompts that work effectively across different LLMs.
- Task-specific Refinement: Tailors prompts for specific types of tasks or domains.
TextGrad in Prompt Optimization
TextGrad is a framework for optimizing Large Language Models (LLMs) using text-based feedback. It treats natural language as a differentiable signal, allowing AI systems to learn and improve through textual inputs rather than traditional numerical data.
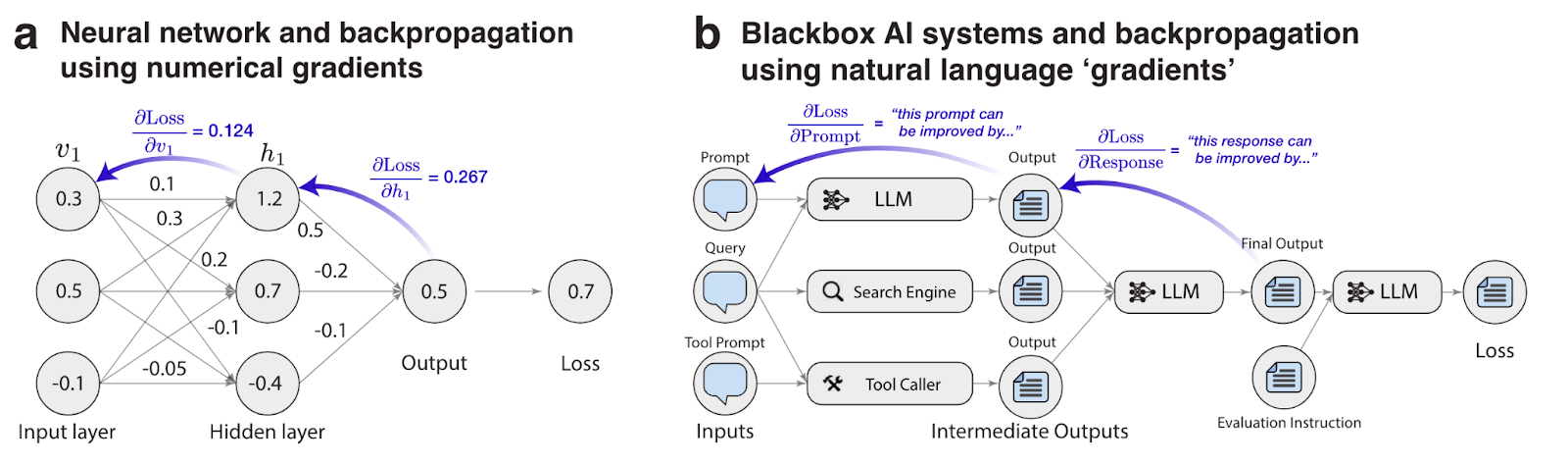 The TextGrad framework process
The TextGrad framework process
The framework operates through the following steps:
- Define an initial solution
- Create a loss function based on a system prompt
- Calculate gradients from the LLM’s text feedback
- Update the model’s parameters using an optimizer
This process enables the refinement of solutions across various applications, from code optimization to scientific problem-solving.
Achievements
TextGrad has demonstrated success in several areas:
Code Optimization: Improved AI models’ performance on challenging coding problems from LeetCode, achieving a 20% performance gain by identifying and addressing edge cases 1.
Question Answering: Increased the zero-shot accuracy of GPT-4 in the Google-Proof Question Answering benchmark from 51% to 55%, the highest known result for this dataset 12.
Medical Applications: Optimized radiotherapy treatment plans by fine-tuning hyperparameter to better target tumors while minimizing damage to healthy tissues 13.
Scientific Problem-Solving: Showed potential in optimizing complex solutions in fields like chemistry and medicine, where traditional optimization methods may struggle 4.
Future Directions and Challenges
As the field of prompt engineering evolves, several key areas are emerging for future development:
 Mind map of future directions and challenges in prompt engineering
Mind map of future directions and challenges in prompt engineering
- Automated Prompt Generation: AI systems that can generate and optimize prompts without human intervention.
- Cross-model Compatibility: Developing universal prompting techniques that work across different LLM architectures.
- Standardization: Establishing industry standards for prompt engineering and compilation.
Challenges that remain include:
- Balancing Automation and Control: Finding the right balance between automated optimization and human oversight.
- Handling Complex Tasks: Developing prompting techniques for increasingly complex and multi-step tasks.
- Privacy and Security: Ensuring that advanced prompting techniques do not compromise data privacy or system security.
Conclusion
The field of prompt engineering is evolving from an art form to a more systematic science. Tools like DSPy and techniques such as prompt compiling and TextGrad are paving the way for more efficient, reliable, and scalable interactions with language models. As these technologies continue to advance, they promise to unlock new possibilities in AI applications while addressing the limitations of traditional approaches.
References
Nair, S., Savarese, P., & Nie, W. (2023). TextGrad: Advancing LLM Performance through Text-Based Gradient Optimization. arXiv preprint arXiv:2310.08117. ↩︎ ↩︎2 ↩︎3
Khattab, O., Iyer, S., Ma, K., Agrawal, A., Chen, D., & Raghunathan, A. (2023). DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv preprint arXiv:2310.03714. ↩︎
Zhu, Y., Liu, J., & Jiang, J. (2023). Prompt optimization techniques for Large Language Models: A survey. arXiv preprint arXiv:2310.04455. ↩︎
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language Models are few-shot learners. arXiv preprint arXiv:2005.14165. ↩︎